ISO 17100:2015, ISO 27001:2017 and ISO 18587 certified translation and localisation services
The idea of using numbers to represent words, or texts made up of words, is “as old as time”. Texts are converted into number sequences in a process of encryption; then in the process of decryption the reverse operation is performed, in a manner known only to the intended recipient. In this way, the encrypted message cannot fall into the wrong hands. Encrypting tools are reported to have been used even in ancient Greece: “A narrow strip of parchment or leather was wound onto a cane, and text was written along it on the touching edges. The addressee, having a cane of the same thickness, could quickly read the text of the message. When unfurled, to show meaningless scattered letters, it would be of no use to a third party; it was understandable only to the intended recipient, who would match it to his template” (https://en.wikipedia.org/wiki/Scytale).
As early as 1949 the American mathematician Warren Weaver formulated the thesis that methods of encryption and decryption might be applied automatically – with the use of calculating machines – to translate text from one language to another. However, his vision would come to pass only 65 years later, when the first articles appeared on the practical use of neural networks in machine translation. Why not earlier? No doubt because nobody was then able to represent text numerically in such a way that the operations performed by neural networks would not cause the meaning to be lost.
It would seem at first sight that words could be represented in the form of successive natural numbers – in alphabetical order, for example – at least within the scope of the document being processed. Let us assume, then, that we wish to process with a computer (for purposes of translation or knowledge extraction, say) a document consisting of the following four sentences:
Austria’s capital is Vienna.
Australia’s capital is Canberra.
Austria’s currency is euros.
Australia’s currency is dollars.
To enable the methods of machine learning to be applied, this document must be converted to numerical form. So let us arrange all the words appearing in the text in alphabetical order (ignoring the issue of upper and lower case letters), and then assign successive natural numbers to the words in this sequence:
australia’s: 1
austria’s: 2
canberra: 3
capital: 4
currency: 5
dollars: 6
euros: 7
is: 8
vienna: 9
Let us suppose that each of the above four sentences is to be presented as a vector of the words appearing in it, with each word represented by its corresponding number. The first two sentences will then appear as follows:
Austria’s capital is Vienna → {2, 4, 8, 9}
Australia’s capital is Canberra → {1, 4, 8, 3}
We would now like to define a numeric representation for both of the above sentences in combination. The natural operation would appear to be addition of the two vectors:
{2, 4, 8, 9} +
{1, 4, 8, 3} =
{3, 8, 16, 12}
The resulting vector contains two values that do not index a word appearing in the document (16 and12), as well as values corresponding to the words “canberra” and “is”. It turns out that the occurrences of “austria’s” and “australia’s” summed to “canberra”, and the two occurrences of the word “capital” summed to give the word “is”!
Neural networks can of course perform much more complex operations on numbers (apart from adding, they can also multiply and apply functions); however, if using the above representation, calculations of this type would be founded on the unjustified assumption that, for example, the word “canberra” has a value which is the sum of the values of the words “austria’s” and ‘australia’s”, which makes no sense semantically. For this reason, it is necessary to look for a completely different way of representing words in numerical form.
Let us assume that all words have the same value of exactly 1. We again order the set of words contained in a document in a certain defined manner (alphabetically, say), but this time representing each word with a vector, having the value 1 in the appropriate (“hot”) position, and zero everywhere else.
For example, the word “australia’s” (first in the alphabetical sequence) has a 1 in the first position:
{1, 0, 0, 0, 0, 0, 0, 0, 0}
while the word “capital” (fourth in the sequence) has a 1 in the fourth position:
{0, 0, 0, 1, 0, 0, 0, 0, 0}
The representation of a whole sentence is now obtained by determining the logical sum of the vectors corresponding to all of the words in the sentence (where the logical sum of two 1’s is 1). For example, the representation of the sentence:
Austria’s capital is Vienna
Is determined as follows:
{0, 1, 0, 0, 0, 0, 0, 0, 0} +
{0, 0, 0, 1, 0, 0, 0, 0, 0} +
{0, 0, 0, 0, 0, 0, 0, 1, 0} +
{0, 0, 0, 0, 0, 0, 0, 0, 1} =
{0, 1, 0, 1, 0, 0, 0, 1, 1}
We can use a similar procedure to combine the information contained in sentences. For example, the combined representation of the first and second sentences (“Austria’s capital is Vienna” and “Australia’s capital is Canberra”) takes the form:
{1, 1, 1, 1, 0, 0, 0, 1, 1}
This vector has 1’s in the positions corresponding to the words that appear in either the first or the second sentence.
The representation of the whole document (all four sentences given above) has the form:
{1, 1, 1, 1, 1, 1, 1, 1, 1}
This method of representing words numerically is known as one-hot encoding.
An obvious drawback of one-hot encoding is the fact that it takes no account of how many times particular words appear. Even if the word “capital” appears 1000 times in a given document, it will be given the same weight as the word “kale”, as long as the latter appears at least once in the document (even by mistake). A system attempting to identify the topic of that document might mistakenly conclude that the text concerns healthy eating, rather than political administration.
A commonly used coding method, therefore, is based on number of occurrences: the vector contains the numbers of instances of particular words. In this case, our four-sentence document might be coded as:
{1, 1, 1, 1, 0, 0, 0, 1, 1}
For example, the word “is”, which corresponds to the eighth element of the vector, appears in the document four times.
In sets consisting of multiple documents, counting occurrences of words will favour those that appear in longer documents (there will naturally be more occurrences of words in those documents). To give “equal chances” to words that come from shorter documents, a representation based on term frequency is used. Here, the number of instances of a word is divided by the total number of words in the document in question. Accordingly, our example document is represented by the following vector, in which each number representing the count of instances of a particular word is divided by 16 (the total number of words in the document):
{1/8, 1/8, 1/16, 1/8, 1/8, 1/16, 1/16, 1/4, 1/16}
The expression term frequency can be abbreviated to TF.
Consider a computer system designed to identify the topic of a given text. It would seem appropriate to take account, first of all, of those words that occur in the text with the highest frequency. But is that the right approach? In our example document the most frequently occurring word is found to be “is”, which unfortunately gives us little idea what the topic might be.
This problem can be overcome using TF-IDF representation. This takes account of the frequency of particular words in the document (TF), but reduces the value of common, “uninformative” words (“is”, “the”, “in”, etc.) by applying a second factor, called the inverse document frequency, or IDF.
Let us assume that apart from our example document, the system also has three other documents to analyse (we are thus dealing with a set of four documents in all). Let us also assume that each of the other three documents contains the word “is”, but none of them contains any of the other words used in our example document. A word’s IDF is calculated as the total number of documents in the set divided by the number of documents containing that word. For the word “is” the IDF is 1 (4/4), while for the other words it is 4 (4/1).
In the TF-IDF representation, the two factors (TF and IDF) are multiplied (in practice the second one is usually transformed using a logarithmic function, but we overlook this detail for the moment). The TF-IDF representation of our example document will therefore be:
{1/2, 1/2, 1/4, 1/2, 1/2, 1/4, 1/4, 1/4, 1/4}
This is more like what we expect! The words with the highest value are now “Austria’s”, “Australia’s”, “capital” and “currency”, which accurately reflect the topic of the text under analysis.
The one-hot representation and frequency-based representation provide information on the relationship between words and documents (they indicate whether a word appears in a document, how frequently it appears, and how that frequency compares with its frequency in other documents). However, they provide no information as to the meanings of the analysed words.
Does there exist any way of representing numerically the meaning of words? We are helped here by the distributional hypothesis, which says that words appearing in similar contexts within large sets of text data are likely to have similar meanings.
Our example document largely confirms that hypothesis: pairs of words appearing there in similar contexts include <dollars, euros>, <canberra, vienna> and <capital, currency>. The first two of these pairs can readily be seen to consist of words of similar meaning.
It is quite likely that the words “canberra” and “vienna” will also appear in similar contexts in other documents. However, the probability that the words from the last pair, “capital” and “currency”, will appear in similar contexts would seem to be much lower. It is for this reason that the statement of the distributional hypothesis refers to “large sets of text data”.
Let us now try, for the words “austria’s” and “australia’s”, which have similar meaning, to build their vector representation using information about the words that occur together with them in the same sentences within our example document.
Recall that our example document looks like this:
Austria’s capital is Vienna.
Australia’s capital is Canberra.
Austria’s currency is euros.
Australia’s currency is dollars.
The words appearing in the above document, arranged in alphabetical order, are as follows:
australia’s: 1
austria’s:: 2
canberra: 3
capital: 4
currency: 5
dollars: 6
euros: 7
is: 8
vienna: 9
Based on the first sentence of the document, we will now build a vector for the word “austria’s”, containing information about the number of instances of words that co-occur with it in the analysed sentence (a 1 appears in the positions corresponding to the words “capital”, “is” and “vienna”, and the remaining places have 0):
{0, 0, 0, 1, 0, 0, 0, 1, 1}
We can build a similar vector for the word “australia’s” based on the second sentence in the document:
{0, 0, 1, 1, 0, 0, 0, 1, 0}
These vectors are quite similar to each other: they differ in only two places out of nine.
In a similar way, we can build vectors for the same two words based on the third and fourth sentences
{0, 0, 0, 0, 1, 0, 1, 1, 0} (vector of words co-occurring with “austria’s”)
{0, 0, 0, 0, 1, 1, 0, 1, 0} (vector of words co-occurring with “australia’s”)
We can now sum the two vectors for the word “austria’s”:
{0, 0, 0, 1, 0, 0, 0, 1, 1} +
{0, 0, 0, 0, 1, 0, 1, 1, 0} =
{0, 0, 0, 1, 1, 0, 1, 2, 1}
Similarly, we can sum the information from the two vectors for the word “australia’s”:
{0, 0, 1, 1, 0, 0, 0, 1, 0} +
{0, 0, 0, 0, 1, 1, 0, 1, 0} =
{0, 0, 1, 1, 1, 1, 0, 2, 0}
Are the vectors computed for the words “austria’s” and “australia’s” over the whole document similar to each other? We can try to determine this similarity by computation.
Is there a simple formula for calculating the similarity of vectors representing different words? There is. It is based on cosine similarity, a value that always lies in the range from 0 to 1. For identical vectors, the similarity is 1; for vectors that are as different from each other as possible, the similarity is 0.
This is the formula:

We first calculate the scalar product of the vectors representing the words “austria’s” and “australia’s” respectively (the numerator in the formula):
A * B = (0 + 0 + 0 + 1 + 1 + 0 + 0 + 4 + 0) = 6
Then we calculate the Euclidean lengths of the vectors (which appear in the denominator):
||A|| = sqrt(1 + 1 + 1 + 4 + 1) = sqrt(8)
||B|| = sqrt(1 + 1 + 1 + 1 + 4) = sqrt(8)
similarity = 6 / (sqrt(8) * sqrt(8)) = 3/4
It turns out that the measure of the similarity between the two vectors is indeed quite high.
The problem with the representation based on the distributional hypothesis is the dimension of the vectors involved. This is equal to the number of different words appearing in the whole set of documents, which in extreme cases may reach into the millions. Vectors with such large numbers of elements are not suited to neural network calculation, for example.
Word2Vec is a representation for words that is based on the distributional hypothesis, but has the additional property that the vector dimension will be no larger than a few hundred. Moreover, the dimension does not depend on the size of the dictionary, but may be specified arbitrarily by the system architect. The Word2Vec representation thus reflects the relation of similarity between words, while at the same time enabling the completion of NLP tasks (machine translation, sentiment analysis, automatic text generation, etc.) with the use of neural networks.
The output below contains lists of words whose vectors, computed on the basis of Wikipedia texts, are the most similar to the vectors for the words given at the top of the columns: “nagoya” for the left-hand column, and “coffee” for the right-hand column. This means that these are the words for which the measure of similarity attains its highest value.

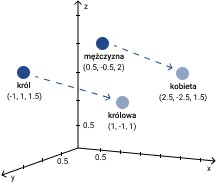
There exist many ways of representing words with numbers. Currently the most popular are numerical vectors constructed by the Word2Vec method. The dimension of such a vector is defined by the system architect; there are most commonly between 300 and 500 coordinates. The vectors reflect the meanings of words in such a way that words of similar meaning correspond to vectors for which the similarity measure takes a high value.