ISO 17100:2015, ISO 27001:2017 and ISO 18587 certified translation and localisation services
A model is a representation of some entity, serving to make it easier to work with. A model is often a miniature version of an object. When playing with a miniature model of an aeroplane, a child can add or subtract various components – mount wings, for example, or remove an engine. In an atlas or on a globe, which represent the Earth, we can cover hundreds or thousands of miles with just one sweep of a finger. On the other hand, if we want to observe the motion of elementary particles, the model of the atom must be a great deal larger than the original. A model as a representation of something makes it easier for us to understand and get to know that thing, from the general concept to detailed properties.
A model may be created for use in a computer application. A digital model of the architecture of a building makes it easier to make changes to the plans – modification can be performed by a human in a computer environment. Sound is modelled in a computer using a digital representation, which a program can transform (by raising the pitch of an utterance, for example) even without human intervention.
A computer language model is a representation of a language which enables a computer to perform certain operations, such as analysing the meaning of a text, carrying out instructions expressed in the language, or correctly translating a text into another language. When we speak of a computer language model (or language model for short), we usually have in mind a representation of just the text itself, omitting additional information about the sound of speech such as pitch or intonation.
In the 20th century it was believed that a language used by humans (a natural language) could be written in the form of rules. Every language was thought to be governed by some finite set of rules indicating how to put words together to form a correct sentence. Moreover, the rules were supposed to make it possible to identify the components from which a given sentence was built, and then to determine its meaning.
In the case of Polish, for example, the following three rules make it possible to formulate simple sentences:
According to these rules, one might create the following simple sentence, for instance:
Szary kotek pije wodę. (The grey cat drinks water.)
The first component of the sentence is the “subject part”, szary kotek (grey cat), built from an adjective in the nominative, szary (grey), and a noun also in the nominative, kotek (cat). The second component is the “predicate part”, pije wodę (drinks water), composed of a verb, pije (drinks), and a noun in the accusative, wodę (water).
Knowing the basic components of a sentence, its meaning can be determined. For example, it can be assumed that the “subject part” denotes the performer of an action, the verb denotes the action, and the noun in the accusative denotes the object being acted on. For example, in the sentence above, the performer of the action is a grey cat, the action is drinking, and the thing being drunk is water.
To date, unfortunately, it has not proved possible to create a set of rules for any language satisfying the following two requirements:
The difficulty in satisfying the first condition results from the fact that people are unbelievably creative in thinking up language constructions that philosophers would not have dreamed of (to convince yourself of this, just listen to politicians). The difficulty in satisfying the second requirement can be illustrated with the following sentence: The barren bus sounds a cat. Although this sentence conforms to the basic rules of English grammar (analogous to those given above for Polish), it does not make any sense. Surely nobody has ever spoken such a sentence elsewhere, and surely it won’t be repeated. It should not, therefore, be considered a correct English sentence.
A text corpus (plural: corpora) is a set of documents collected in one place to enable analyses to be performed on the entire collection of texts. For example, a set of the complete works of Shakespeare placed in one location (in a library if they are printed on paper, or on a computer disk if they are in digital form) makes up a text corpus which could be used, for example, to analyse the famous dramatist’s writing style.
The owner of the world’s largest digital corpus is undoubtedly Google. That organisation is able to perform analyses that encompass all of the texts accessible through its search engine.
A statistical model of a language is a representation based on some corpus of texts written in that language. A statistical model of Polish, for example, may be built from the set of all Polish-language texts accessible via the Google search engine.
Models of a given language may be very different from each other if they are built using different corpora. For example, we might construct specialised language models, using a corpus of texts taken exclusively from a particular specialist field.
Scrabble players may sometimes argue about whether a particular word is allowed in the game. In Poland, the arbiter used in such disputes is often the website sjp.pl (the abbreviation stands for słownik języka polskiego, “dictionary of the Polish language”). However, the language is constantly evolving, and a dictionary cannot always keep up with the changes.
But what if a somewhat different rule were adopted, namely that a word is allowed if it appears in a particular corpus – for example, the corpus of Polish texts available in Google? A new word, popular among younger speakers, such as plażing (“beaching”), might be deemed inadmissible by sjp.pl, although Google returns over 100,000 examples of its use.
We might, therefore, define a statistical language model for Scrabble, based on Polish-language texts indexed by Google, in the following way: a word is allowed if Google returns more than 1000 occurrences in Polish texts. This threshold is defined arbitrarily, but serves to eliminate words that might be found on the Internet by accident (as a result of typing errors, for instance).
Some words may appear more often in a given corpus, and others less often. We might therefore build a statistical language model that awards higher scores to words with a higher frequency of occurrence. The correctness of a word is evaluated on a scale from 0 (absolutely incorrect) to 1, where the value is obtained by dividing the number of occurrences of that word in the corpus by the total number of words in the corpus. For example, if the word in question appears five times in a corpus consisting of 100 words, its correctness will be 0.05. The correctness of a word that is absent from the corpus, of course, will be 0.
Such a model can also be applied to whole sentences. We calculate in turn the correctness of each word in the sentence, and then multiply all the values together. If any of the words fails to appear in the corpus, the sentence as a whole will be assigned the value 0; otherwise it will be assigned some non-zero value less than 1. A model of this type is called a unigram language model, since each word is considered independently of the others.
We may also try defining a language model as a function which assigns a correctness value between zero and one to any expression in the language (with respect to a given corpus).
For example, we might apply the unigram model described above, based on the Google corpus, to the previously cited sentence The barren bus sounds a cat. This would lead to a certain number larger than zero, since each of the words of this sentence will be confirmed by the corpus. However, this result does not agree with our intuition, since this particular sequence of words appears not to make any sense.
An n-gram language model, on the other hand, takes account of the occurrence of words in particular contexts. For example, a bigram model checks, for a given pair of words, how frequently the second word occurs immediately after the first. Google returns several million occurrences of the word barren, but only a few hundred in which it is followed by the word “bus”. This means that the correctness of the word pair barren bus is assessed as close to zero.
A bigram language model determines the correctness of all pairs of words appearing in a sentence (barren bus, bus sounds, etc.), and then multiplies the values together. If the sentence makes no sense, the resulting final value will be very close to zero.
In a similar way, one can construct 3-gram (trigram) or 4-gram language models. Models based on sequences of more than four words are not normally used.
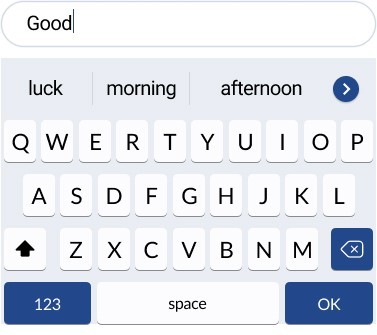
The best-known application of language models is predictive text, used when typing text messages on a phone. After you type the first word of your message, the system suggests the next one. After each word, it comes up with a new set of suggestions.
How does this work? The system suggests words which, in combination with the preceding ones, give the highest correctness value (that is, they occur most frequently in the corpus). So if you begin by typing the word Good, the system might suggest that, according to the corpus it is using, the most “correct” continuations would be Good luck, Good morning or Good afternoon.
In the case of machine translation, the system first generates several potential ways of translating a sentence – differing in, for example, the choice between words of similar meaning or the word order. The language model then suggests which of the possibilities is most correct – and that text is supplied by the system as the translated sentence.
Language models perform a similar function in speech recognition. It is the model that decides that, for example, a dictated sentence is to be represented as “Let’s meet at four”, and not, for example, “Let’s meat at four” or “Let’s meet at fore”, even though all three of these versions sound the same.
A statistical language model is a method of representing a natural language based on a defined text corpus. Such a model awards higher scores to texts consisting of words and phrases that appear in the corpus more frequently.
A limitation of statistical language models, however, is that they take account only of associations between adjacent words. Let us look at the following example sentence:
The above contract contains errors of substance, and therefore it cannot be signed.
In this sentence, the words contract and signed occur at a long distance from each other (with as many as nine intervening words). A statistical language model is not able to detect that there is any semantic relation between these words, even though they refer to the same action: the signing of a contract.
Distant associations of this type are nonetheless detectable using neural network language models. Although the basic role of such models is similar to that of statistical models – they determine the degree of correctness of a text with respect to a particular corpus – the method of computing the correctness is different. The sophisticated structure of neural networks means that they are also able to take account of relationships between distant words.