ISO 17100:2015, ISO 27001:2017 and ISO 18587 certified translation and localisation services
By artificial intelligence, we mean a computer system carrying out tasks that require a computational environment of a complexity comparable to that of the human brain. The term artificial intelligence is not applied to the ability to add numbers, for example, as this can be achieved with a simple mechanical device (the first calculator capable of performing all four arithmetic operations was built in 1810, by Abraham Stern of Hrubieszów). Examples of tasks requiring the use of artificial intelligence include image recognition, speech recognition, and high-risk decision making.
Translating correctly from one language to another requires the knowledge and skill of an educated human being. For this reason, automatic translation (machine translation) is regarded as a task relevant to the field of artificial intelligence.
Machine translation means the translation of texts by a computer without human involvement. This may be contrasted with computer-assisted translation, which is performed by a human with the aid of a computer.
Machine translation is faster and less costly than computer-assisted translation, but on the other hand it is less precise. For this reason it is frequently claimed that machine translation merely conveys the sense of the original text, and hence cannot be regarded as a reliable source of knowledge.
In computer-assisted translation, the final decision on the form of the translated text is made by a human. The translator’s work is supported by digital tools including multilingual dictionaries, thesauruses containing information on synonyms and antonyms, and specialist lexicons. Particularly useful for the translator is a translation memory – a database storing sentences and phrases that have been translated before.
Machine translation systems are classed as belonging to the field of artificial intelligence, but this does not apply to tools for computer-assisted translation.
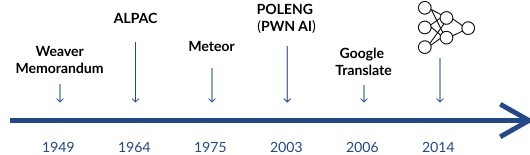
The start of the machine translation era is usually dated to a memorandum written by the American mathematician Warren Weaver. In 1949, at the request of the Rockefeller Foundation, he published a paper titled Translation, in which he considered the possibility of having texts translated by a computer. Warren believed that this task would be feasible in the near future, using methods analogous to those used in cryptography for the decoding of secret messages. Weaver’s memorandum provided an impetus for research in automatic translation, mainly in the United States.
Warren’s ideas received confirmation from a 1953 experiment conducted jointly by Georgetown University and IBM. Here an automatic translation system was presented, equipped with a small vocabulary (250 words) and several rules (for example, on the transposition of adjacent words). The operator of the system, who did not speak Russian, used punched cards to input more than 60 Russian sentences, written out phonetically in the Latin alphabet. The system then printed out English translations of those sentences. The demonstration was a complete success – partly because the source sentences had been carefully selected, and their translations were subject to verification.
In the following years, systems were constructed that marked out potential directions for development in the field, although they used only limited vocabularies. A translation system built in 1955 by A. D. Booth was based on a more extensive bilingual lexicon, whereas the machine of G. W. King (1960) foreshadowed a method that would be developed theoretically 30 years later, namely translation based on statistics. However, progress in translation quality in subsequent years fell well short of the expectations engendered by the experiment in Georgetown.
In 1964, a group of United States government institutions – the Department of Defense, the National Science Foundation and the CIA – set up a committee under the name ALPAC (Automatic Language Processing Advisory Committee) to review expectations regarding the development of machine translation. After two years of work, in 1966 the committee published a report that was devastating for researchers in the field. It concluded, among other things, that the quality of machine translation was markedly lower than that of human translation, and that its cost ($66 for 1000 words) and speed (50 pages in 15 days) in no way justified the investment of further funds in this area of research.
While the halting of government funding brought academic work on automatic translation to a standstill, it led to the formation of private commercial organisations. In 1968 the company Systran was established in California (still active, it is now based in Paris). Systran initially supplied automatic translation services to the US Department of Defense, and later to the European Commission. Until 2007, Systran solutions also formed the core of the Google Translate system.
Another system that played a significant role in popularising machine translation was Meteor, developed in 1975, and applied effectively from 1981 to 2001. Meteor translated weather reports between the two official languages of Canada: English and French. Although the entire system could fit on a single 1.44 MB floppy disk, it could translate as many as 30 million words a year – at a rate of 20 pages a second. Moreover, the translation quality offered by Meteor was estimated at 97%, a result way beyond the reach of today’s systems. However, this was possible only because of the extremely limited syntax and vocabulary appearing in the texts that this system translated.
Automatic translation systems appeared on the Polish market at the start of the 21st century. The first commercial product of this type was English Translator XT from Techland, which was based on a bilingual lexicon and several grammatical rules, to enable it to choose appropriate forms of words in the translated text. Soon, Kompas launched a product called Tłumacz i słownik (Translator and Dictionary), which could translate between Polish and six foreign languages: English, German, Russian, Italian, Spanish and French. Its authors placed emphasis on the extensive size of the dictionary, which had several million headwords, and besides single words also contained multiword expressions.

In 1996 a group of computer scientists from Adam Mickiewicz University in Poznań began work on a system for automatic translation from Polish to English. In 2001 the development of the system, called Poleng, was given a boost by Allied Irish Bank (AIB), then a shareholder of the Polish bank WBK. AIB wanted to customise the system to facilitate internal communication between its Polish and British staff. In 2003 the POLENG company was founded, its shareholders being the authors of the translation system and an outside investor, POLENG Scientific Publishers.
Using as a basis the POLENG–Oxford Polish–English dictionary of 2004, POLENG created a machine translation system called Translatica, which operates using “deep syntactic analysis”. For each translated sentence, the system constructs a representation in the form of a syntactic tree, and then, by means of appropriate rules, converts this tree into a corresponding tree for the target language. On the basis of this, the translated sentence is then generated. The Translatica system is still available today at www.translatica.pl.
In 2006 the free Google Translate site was launched, and a year later it began offering automatic translation for Polish. The quality of the translations offered was poorer than that of commercial systems (a report published in 2011 indicated that in tests, Translatica achieved a higher level of quality than Google Translate). Nonetheless, Google’s free system gradually forced its commercial counterparts out of the marketplace. Being based on statistical methods, Google Translate was much cheaper to develop, and over time, thanks to access to vast and continuously growing text resources, the quality of its translations improved. An undoubted key factor behind its success, however, was the fact that its services were available free of charge.
In the 1990s, research in automatic translation gradually began to shift from a rule-based approach to statistical methods, based on the analysis of huge sets of data. Google Translate showed that academically developed solutions could find practical applications in business.
In 2014 two independent groups of researchers, from Google and from the University of Montreal, proposed machine translation systems based on neural networks. Since that time enormous progress has been made in the quality of automatic translations, through enhancements to neural network architecture.
A very important role in the development of neural network translation has been played by researchers at Adam Mickiewicz University in Poznań, in collaboration with POLENG. Marcin Junczys-Dowmunt and Tomasz Dwojak are the leading co-authors of a system called Marian NMT (marian-nmt.github.io), which is currently being developed by Microsoft. This is an open platform enabling the creation of a neural network system for automatic translation based on private linguistic resources.
Neural network translation systems have not yet reached the full extent of their capabilities. In coming years, further progress can be expected in this field, thanks to the continued evolution of neural network architecture. Higher quality will also be achieved by adapting systems to translate texts in narrowly defined specialist fields.