ISO 17100:2015, ISO 27001:2017 and ISO 18587 certified translation and localisation services
Artificial intelligence (AI) is a type of computer system whose task is to imitate actions performed by a human.
How can we evaluate whether an AI system performs its task effectively? I will try to answer that question in this blog.
For a long time it was believed that chess, the king among board games, was so complex that no digital machine would ever be able to defeat a human grandmaster. The first time a computer (specifically, the program Deep Blue) beat the world champion (Garry Kasparov) was in 1996 – although it should be recalled that Kasparov came back to win several succeeding games. Since that time computing power has grown so much that today, even the greatest human genius would not stand a chance if pitted against an “expert” machine.
In 2016 another bastion of human domination fell to the machines. The program AlphaGo defeated champion go player Lee Seedol 4 games to 1. One of the last remaining domains of human intellect in the games world is bridge. While we are putting up a spirited defence against the barbarian computers, here too it is clear that our days are numbered.
We may thus propose the following criterion for positive assessment of the effectiveness of artificial intelligence in the field of games: AI plays a game effectively if it can defeat the human world champion.
Artificial intelligence methods perform extremely well at tasks that are defined by rigid rules. This is the reason why they cope so well with games, where the rules are precisely laid down. In tasks involving the perception of elements of reality – where such rigid rules no longer apply – the competences of the “Matrix” remain, for the moment, behind those of human beings.

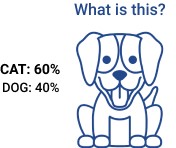
Even a three-year-old child will easily recognise that the above photo shows a dog and not a cat. Unfortunately, even an advanced system of artificial intelligence will not be able to answer the question with absolute certainty. (The system presented identifies the image as a dog with 97% certainty, but in the end... who can be sure?)
In the case of perception of the outside world, we do not expect more from AI than we can do ourselves. Instead, comparing its results with those obtained by human perception, we are satisfied if the machine at least comes close to human competence. So what benefit do we derive by using AI, if its interpretation of reality is imperfect? The advantage is that it can perform such tasks incredibly fast. An AI system can look through millions of images a second, and automatically select – even with only 97% certainty – all those that contain a dog. A well-rested human might be able to perform the same task without ever making a mistake, but could process no more than a few images per second.
To evaluate the effectiveness of a computer system in tasks concerning the perception of outside reality, the results achieved by artificial intelligence are compared with those achieved by human perception. We consider that the system performs effectively if there is a high correspondence between what the computer records and what a human perceives. An example task is the identification of spam.
To evaluate the effectiveness of a system, we take a sample – 100 randomly selected e-mail messages, for instance – and then ask a human to classify each of them as either SPAM or NON-SPAM.
The sample with all of the objects classified by a human being is called a gold standard.
Accuracy is a measure that tells us what proportion of the objects in the gold standard sample were classified by the system in accordance with the human assessor’s decision. For example, if the system classifies all of the e-mails in the same way as the human did, its accuracy is 100%. A classifier that achieves an accuracy above 90% can be considered effective.
However, a high accuracy value does not always mean that the system meets our expectations. Let us modify the task to be given to the artificial intelligence system, now defining it as follows: “Identify all e-mails that relate to tourism.”
Assume that three out of the 100 e-mails in the gold standard sample were classified by a human as relating to tourism (in accordance with a typical distribution of the subjects of e-mail correspondence received by a random user), with the remaining 97 being on other subjects. Now imagine that after months of hard work we have developed an AI system that will identify tourism-related e-mails with an accuracy of 95%. Doesn’t sound bad?
But suppose someone else came up with an entirely different idea: they developed a system that achieves higher accuracy by simply classifying all e-mails as not related to tourism. That system, based on the gold standard, will attain an accuracy of 97%!
What conclusion can we draw from this? Accuracy is not a useful measure in a situation where one of the classes is significantly larger than the others. In that case, we need to look for other measures of effectiveness.
Precision is a measure that indicates what proportion of the objects assigned by the system to a class that interests us have been assigned correctly. For example, if our AI system identifies four tourism-related e-mails among the 100 objects in the gold standard sample, and they include the three that were classified as tourism-related by the human assessor, then the precision will amount to 75%.
Of course, this is not a bad result. But again, someone else may produce a system that identifies only one e-mail as relating to tourism, but does so correctly. The precision achieved by that solution will be 100%, even though it overlooked two out of the three relevant objects!
Yet another criterion for evaluation is therefore needed.
Recall is a measure that tells us what proportion of the objects belonging to the class that interests us were correctly identified by the system. In terms of this measure, our solution is unbeatable – it achieves a recall value of 100%, while the aforementioned system that identified just one e-mail about tourism manages only 33%!
Our satisfaction will be short-lived, however, because again someone will quickly develop a solution that identifies as many as 10 tourism-related e-mails, again including the three that were classified as such by a human. This program will record lower precision (just 30%), but in terms of recall it will attain a score of 100%, equal to ours.
So what can we do about this?
The conclusion is that an objective measure serving to evaluate the effectiveness of an artificial intelligence system ought to take account of both precision and recall. This condition is satisfied by a value called the F-measure, which is the harmonic mean of the two aforementioned measures, or twice their product divided by their sum.
Let us compute the F-measure for our solution. First compute the product 2 x 75% x 100%, which gives 150%. Then divide this result by the sum of the measures, namely by 75% + 100% = 175%. This gives an F-measure of 85.7%.
The F-measure for the solution that identified only one object is calculated as follows:
2 x 100% x 33.3% / 133.3% = 50%
while for the solution that identified 10 objects, the F-measure is
2 x 30% x 100% / 130% = 46.2%.
There is some justice in this world after all!
You may ask: why complicate life by defining this last measure of quality as the harmonic mean of the two values, and not as the universally understood arithmetic mean?
The idea is to reward those solutions for which the two measures “co-exist in harmony”. For example, for an object classifier that achieves precision and recall both equal to 50%, both the arithmetic and the harmonic mean will be 50%. However, if we “turn the screw too tight” and construct a solution with a high precision of 90%, at the cost of a low recall of 10%, the arithmetic mean of the two measures will again be 50%, while the harmonic mean will fall markedly – precisely, to a value of 18%.
In working to ensure high precision, we should not forget about maintaining high recall – and vice versa!