Usługi tłumaczeniowe i lokalizacyjne certyfikowane normami ISO 17100:2015, ISO 27001:2017 oraz ISO 18587
Sztuczna inteligencja (ang. Artificial Intelligence lub w skrócie: AI) to system komputerowy, którego zadaniem jest naśladowanie czynności wykonywanych przez człowieka.
Jak ocenić, czy system AI wykonuje swoje zadanie skutecznie? Na to pytanie postaram się odpowiedzieć w niniejszym wpisie..
Przez długi czas wierzono, iż królewska gra planszowa, jaką są szachy, jest tak skomplikowana, że maszyna cyfrowa nigdy nie będzie w stanie pokonać szachowego arcymistrza. Pierwszy raz komputer (a konkretnie program Deep Blue) zwyciężył mistrza świata w roku 1996 – choć trzeba wspomnieć, że w kilku następnych partiach Garri Kasparow skutecznie mu się “odgryzł”. Wzrost mocy obliczeniowych w kolejnych latach spowodował jednak, że dziś nawet najwspanialszy geniusz ludzki nie ma najmniejszych szans w starciu z “komputerowym rzemieślnikiem”.
W roku 2016 padł kolejny bastion ludzkiej dominacji. Program o nazwie AlphaGo pokonał w stosunku 4 do 1 Lee Seedola – mistrza gry w go. Jedną z ostatnich domen ludzkiego intelektu w obszarze gier pozostaje więc brydż. Bronimy się co prawda dzielnie przed komputerowymi barbarzyńcami, lecz i tu nasze dni są już najwyraźniej policzone.
Możemy zatem zaryzykować następujące kryterium pozytywnej oceny skuteczności sztucznej inteligencji w dziedzinie gier: sztuczna inteligencja gra skutecznie, jeśli wygrywa z mistrzem świata.
Metody sztucznej inteligencji sprawdzają się bardzo dobrze w zadaniach określonych sztywnymi regułami. Właśnie dlatego tak świetnie radzą sobie w grach – których zasady są precyzyjnie ustalone. W zadaniach związanych z postrzeganiem otaczającej rzeczywistości – gdzie nie obowiązują już tak sztywne reguły – kompetencje “Matrixa” pozostają jednak póki co w tyle za umiejętnościami człowieka.

https://deepomatic.com/en/introduction-to-computer-vision-and-image-recognition/
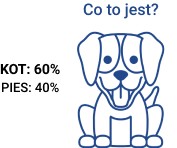
Nawet trzyletnie dziecko bez trudu rozpozna, że na powyższym obrazku przedstawiony jest pies, a nie kot. Zaawansowany system sztucznej inteligencji nie będzie miał niestety aż tak niezachwianej pewności w tym względzie (według niego zapewne jest to pies – 97%, ale ostatecznie... kto wie?).
W przypadku postrzegania zewnętrznego świata nie oczekujemy od sztucznej inteligencji więcej niż od samych siebie. Wręcz przeciwnie: porównujemy skutki jej działania z efektami percepcji ludzkiej i jesteśmy usatysfakcjonowani, gdy kompetencje maszyny okazują się przynajmniej zbliżone do umiejętności człowieka. Jaką mamy zatem korzyść z zastosowania sztucznej inteligencji, jeśli postrzega ona rzeczywistość w sposób niedoskonały? Ano taką, że ona to robi niesłychanie szybko. Sztuczna inteligencja w przeciągu sekundy przegląda miliony obrazków i automatycznie wybiera z nich – nawet jeśli tylko z 97-procentową pewnością – wszystkie te, na których zaprezentowany jest pies. Wypoczęty człowiek być może nie pomyli się w tym względzie ani razu, lecz w ciągu sekundy jest w stanie przeanalizować co najwyżej kilka obrazków.
W celu oceny skuteczności systemu komputerowego w obrębie zadań związanych z postrzeganiem otaczającej nas rzeczywistości efekty działania sztucznej inteligencji porównuje się z wynikami percepcji ludzkiej. Uznajemy, że system działa skutecznie, jeśli zachodzi wysoka zgodność pomiędzy tym, co odnotowuje komputer, a tym, co postrzega człowiek. Posłużmy się w tym względzie przykładem, jakim jest zadanie identyfikacji spamu.
Aby ocenić skuteczność działania systemu, wybieramy pewną próbkę – np. 100 losowo dobranych wiadomości mailowych – po czym prosimy człowieka o zaklasyfikowanie każdej z nich do jednej z dwóch klas: SPAM lub NIE-SPAM.
Próbkę, której wszystkie obiekty zostały zaklasyfikowane przez człowieka, określamy mianem złotego wzorca (ang. golden standard).
Miara dokładności (ang. accuracy) mówi, jaka część obiektów złotego wzorca została przez system zaklasyfikowana w sposób zgodny z decyzjami człowieka. Jeśli na przykład system klasyfikuje wszystkie maile identycznie jak człowiek, miara jego dokładności wynosi 100%. Klasyfikator, który działa z dokładnością powyżej 90%, może zostać uznany za skuteczny.
Wysoka miara dokładności nie zawsze jednak prowadzi do zaspokojenia naszych oczekiwań wobec systemu. Zmodyfikujmy nieco nasze wcześniejsze zadanie dla systemu sztucznej inteligencji, definiując je tym razem w sposób następujący: “Wykryj wszystkie maile, w których mowa jest o turystyce”.
Załóżmy, że w złotym wzorcu 3 spośród 100 maili zaklasyfikowane zostały przez człowieka jako związane z turystyką (zgodnie ze średnim rozkładem tematyki korespondencji elektronicznej trafiającej do przypadkowego odbiorcy), a pozostałe 97 – jako związane z innymi tematami. Wyobraźmy sobie teraz, że po wielu miesiącach żmudnych wysiłków opracowaliśmy wreszcie sztuczną inteligencję, która rozpoznaje maile turystyczne z dokładnością 95%. Całkiem nieźle, prawda?
Tyle tylko, że ktoś inny wpadł tymczasem na zupełnie inny pomysł: opracował mianowicie system, który działa z wyższą dokładnością, gdyż... wszystkie maile klasyfikuje jako NIE-turystyczne, w wyniku czego wykazuje na złotym wzorcu dokładność 97%!
Jaki z tego wniosek? Miara dokładności nie ma praktycznego zastosowania w sytuacji, w której jedna z klas wyraźnie dominuje nad innymi pod względem liczności. Trzeba w takim przypadku poszukać innych miar skuteczności.
Miara precyzji (ang. precision) mówi, jaka część obiektów przypisanych przez system do interesującej nas klasy została wskazana poprawnie. Jeśli na przykład opracowana przez nas sztuczna inteligencja zidentyfikowała cztery maile turystyczne wśród stu objętych złotym wzorcem, przy czym w zbiorze tym faktycznie znalazły się wszystkie trzy wiadomości zaklasyfikowane jako turystyczne przez człowieka, miara precyzji naszego rozwiązania wynosi 75%.
To oczywiście całkiem niezły wynik. Znowuż jednak znalazł się ktoś, kto opracował system, który pośród stu maili zidentyfikował co prawda tylko jeden o tematyce turystycznej, za to w pełni prawidłowo. Miara precyzji jego rozwiązania wynosi zatem 100%, pomimo iż dwa z trzech maili zostały przecież przez jego system pominięte!
Potrzebujemy zatem jeszcze innego kryterium oceny.
Miara pokrycia (ang. recall) mówi, jaka część obiektów należących do interesującej nas klasy została poprawnie wskazana przez system. Pod względem tej miary nasze rozwiązanie okazuje się absolutnie bezkonkurencyjne – osiąga bowiem pokrycie na poziomie 100%, podczas gdy wspomniany powyżej system, który zidentyfikował zaledwie jeden mail o tematyce turystycznej, wykazuje pokrycie na poziomie jedynie 33%!
Nasza radość nie trwa niestety długo, gdyż znowu ktoś błyskawicznie opracował rozwiązanie, które identyfkuje aż 10 maili o tematyce turystycznej – w tym jednak wszystkie trzy zaklasyfikowane jako turystyczne przez człowieka, dzięki czemu jego program działa co prawda gorzej pod względem miary precyzji (osiąga w tym względzie skuteczność na poziomie zaledwie 30%), jednak pod względem pokrycia w pełni dorównuje naszemu (100%).
I jak tu żyć?
Wniosek jest taki, że obiektywna miara ewaluacji skuteczności systemu sztucznej inteligencji powinna brać pod uwagę jednocześnie precyzję oraz pokrycie. Warunek ten spełnia miara F (ang. F-measure), która jest średnią harmoniczną obu powyższych miar: jest to ich podwojony iloczyn podzielony przez ich sumę.
Obliczmy zatem miarę F dla naszego rozwiązania. Najpierw mnożymy: 2 x 75% x 100%, co daje 150%. Następnie dzielimy powyższą wartość przez sumę miar, czyli przez: 75% + 100% = 175%, w wyniku czego otrzymujemy miarę F o wartości 85,7%.
Miara F dla rozwiązania, które wskazało tylko jeden obiekt, wynosi natomiast odpowiednio:
2 x 100% x 33,3% / 133,3% = 50%
podczas gdy miara F dla rozwiązania, które wskazało 10 obiektów wynosi odpowiednio:
2 x 30% x 100% / 130% = 46,2%
Jest jednak na tym świecie jakaś sprawiedliwość!
Można zadać pytanie: Po co komplikować sobie życie, definiując ostateczną miarę jakości jako średnią harmoniczną dwóch wartości, a nie – jako dobrze wszystkim znaną średnią arytmetyczną?
Chodzi o to, żeby premiować rozwiązania, w których obie miary “współżyją w harmonii”.
Na przykład, dla systemu, który klasyfikuje obiekty z wartościami precyzji i pokrycia po 50%, zarówno średnia arytmetyczna, jak i harmoniczna wynoszą równe 50%.
Jeśli jednak za mocno “przykręcimy śrubę” i skonstruujemy rozwiązanie o wysokiej precyzji na poziomie 90% kosztem niskiego pokrycia na poziomie 10%, to średnia arytmetyczna obu miar ponownie wyniesie 50%, jednak średnia harmoniczna wyraźnie spadnie – dokładnie do wartości 18%.
Dbając o wysoką precyzję, nie zapominajmy o zachowaniu wysokiego pokrycia!
I odwrotnie!