Usługi tłumaczeniowe i lokalizacyjne certyfikowane normami ISO 17100:2015, ISO 27001:2017 oraz ISO 18587
Model to reprezentacja jakiegoś bytu, która ułatwia operowanie nim. Model jest często miniaturą pewnego obiektu. W trakcie zabawy miniaturowym modelem samolotu dziecko może dołączyć skrzydła, doklejać albo też demontować różne elementy, np. może od modelu odłączyć silnik. W atlasie czy na globusie, które reprezentują Ziemię, możemy jednym pociągnięciem palca “pokonać” setki lub tysiące kilometrów. Jeśli z kolei chcemy obserwować ruch cząstek elementarnych, model atomu musi być znacznie większy od swego pierwowzoru. Model jako odwzorowanie jakiegoś bytu ułatwia nam poznanie i zrozumienie jego całości, od ogółu do szczegółów.
Model może zostać stworzony po to, aby umożliwić operowanie nim w aplikacji komputerowej. Cyfrowy model architektury budynku pozwala na łatwe dokonywanie zmian w projekcie – modyfikacji dokonuje człowiek w środowisku komputerowym. Dźwięk modelowany jest w komputerze za pomocą reprezentacji cyfrowej, którą program komputerowy może przekształcać (np. podwyższenia tonu wypowiedzi) – nawet bez ingerencji człowieka.
Komputerowy model języka jest taką reprezentacją języka, która umożliwia komputerowi dokonywanie w tym modelu pewnych operacji, takich jak na przykład analiza sensu wypowiedzi, wykonywanie instrukcji wypowiedzianych w danym języku czy poprawne tłumaczenie sformułowanego w nim tekstu na inny język. Gdy mówimy o komputerowym modelu języka (w skrócie: modelu języka), mamy zazwyczaj na myśli reprezentację samego tekstu – z pominięciem takich informacji dźwiękowych jak na przykład intonacja czy wysokość tonu.
W wieku XX wierzono, że język, którym posługuje się człowiek (inaczej: język naturalny), można zapisać za pomocą reguł. Każdym językiem, jak bowiem sądzono, rządzi pewien skończony zbiór reguł, decydujący o tym, jak z wyrazów poprawnie składać zdania. Co więcej, dzięki tym regułom można dla danej wypowiedzi stwierdzić, z jakich składowych jest ona zbudowana, a następnie określić jej znaczenie.
W przypadku języka polskiego następujące trzy reguły umożliwiają przykładowo formułowanie zdań prostych:
Zgodnie z tymi regułami można na przykład utworzyć następujące zdanie proste:
Szary kotek pije wodę.
Pierwszą składową zdania jest “Część podmiotu” szary kotek, zbudowana z przymiotnika w mianowniku (szary) oraz rzeczownika w mianowniku (kotek). Drugą składową zdania stanowi natomiast “Część orzeczenia” pije wodę, zbudowana z czasownika (pije) oraz rzeczownika w bierniku (wodę).
Znając podstawowe składowe zdania, można określić znaczenie wypowiedzi. Można na przykład przyjąć, że Część podmiotu oznacza wykonawcę czynności, czasownik reprezentuje czynność, a rzeczownik w bierniku – obiekt czynności. Znaczenie powyższej wypowiedzi można wtedy przedstawić następująco:
Wykonawca: szary kotek
Czynność: picie
Obiekt: woda
Jak dotąd dla żadnego języka nie udało się niestety stworzyć zestawu reguł, który spełniałby następujące dwa postulaty:
Trudność spełnienia pierwszego postulatu wynika stąd, że ludzie są niewiarygodnie kreatywni w wymyślaniu konstrukcji językowych, o których nie śniło się filozofom (by o tym się przekonać, wystarczy posłuchać polityków). Trudność spełnienia drugiego postulatu można natomiast przedstawić na przykładzie następującego zdania: Jałowy autobus brzmi kotka. Choć zdanie to zgodne jest z trzema podstawowymi regułami polskiej gramatyki, nie ma ono żadnego sensu. Nikt takiego zdania zapewne nigdy nie wypowiedział w innym miejscu i pewnie nie wypowie powtórnie. Nie powinno zatem być ono uznane za zdanie poprawne w języku polskim.
Korpus tekstów to zbiór dokumentów zgromadzonych w jednym miejscu w celu dokonywania w jego ramach zbiorczych analiz. Na przykład zbiór wszystkich dzieł Szekspira umieszczony w jednej lokalizacji (w bibliotece, jeśli są to teksty papierowe, lub na dysku, jeśli są to ich reprezentacje cyfrowe) stanowi korpus tekstów, w obrębie którego można dokonywać analizy stylu pisarskiego wymienionego powyżej wybitnego dramaturga.
Posiadaczem największego cyfrowego korpusu na świecie jest zapewne firma Google, która może dokonywać zbiorczych analiz w ramach wszystkich tekstów, do których ma dostęp jej wyszukiwarka.
Statystyczny model danego języka to jego reprezentacja wyznaczona na podstawie pewnego korpusu tekstów zapisanych w tym języku. Statystyczny model języka polskiego może na przykład zostać zbudowany z wykorzystaniem zestawu wszystkich tekstów zapisanych w języku polskim, do których dostęp ma wyszukiwarka Google.
Modele danego języka mogą znacznie się od siebie różnić, jeśli zbudujemy je na podstawie różnych korpusów. Możemy na przykład konstruować specjalistyczne modele języka, które wyznaczone zostają z wykorzystaniem korpusu tekstów wyłącznie z obszaru danej specjalności.
Gracze w scrabble spierają się czasem, czy dany wyraz jest dopuszczalny. Wyrocznią w tej sprawie jest często portal internetowy sjp.pl (słownik języka polskiego). Język jednak cały czas się rozwija, a słownik nie zawsze za tymi zmianami nadąża.
A gdyby tak przyjąć nieco inne podejście, a mianowicie: Wyraz uważamy za poprawny, jeśli pojawia się on w konkretnym korpusie – na przykład w korpusie tekstów polskich wyszukiwarki Google? Nowopowstały, popularny wśród młodzieży wyraz plażing uznawany jest na przyklad przez sjp.pl za niedopuszczalny, podczas gdy wyszukiwarka Google wskazuje ponad 100 tys. przykładów użycia powyższego słowa.
Możemy zatem zdefiniować statystyczny model języka polskiego dla scrabblistów oparty na polskich tekstach indeksowanych przez Google w sposób następujący: Wyraz uważamy za dopuszczalny, jeśli według wyszukiwarki Google liczba jego wystąpień w tekstach polskich przekracza pułap 1 000. Odpowiedni próg definiujemy w sposób arbitralny, mając na celu eliminację wyrazów, które znalazły się w Internecie przypadkowo (chociażby w wyniku błędu typograficznego).
Niektóre wyrazy występują w danym korpusie częściej, a inne – rzadziej. Można zatem zbudować statystyczny model języka, który da nam możliwość premiowania wyrazów o wyższej częstości występowania. Stopień poprawności danego wyrazu określamy w skali od 0 (całkowicie niepoprawny) do 1, przy czym wyliczamy jego wartość dzieląc liczbę jego wystąpień w korpusie przez liczbę wszystkich zawartych w tym korpusie wyrazów. Jeśli na przykład dany wyraz występuje pięć razy w korpusie składającym się ze stu wyrazów, jego stopień poprawności wynosi 0,05. Stopień poprawności wyrazów spoza korpusu wynosi oczywiście 0.
Powyższy model można zastosować też do całych zdań. Obliczamy po kolei stopień poprawności każdego z wyrazów w zdaniu, a następnie mnożymy przez siebie otrzymane wyniki. Jeśli którykolwiek z wyrazów nie występuje w korpusie, całe zdanie otrzymuje wartość 0; w przeciwnym wypadku zdanie otrzymuje pewną niezerową wartość mniejszą od 1. Tego typu model nazywamy jednowyrazowym modelem języka, gdyż na jego gruncie każdy wyraz rozpatrujemy niezależnie od wyrazów pozostałych.
Możemy pokusić się teraz o definicję modelu języka: Model języka to funkcja, która każdemu wyrażeniu danego języka przydziela liczbę z zakresu od 0 do 1, informującą o jego poprawności (względem pewnego korpusu).
Możemy na przykład zastosować model jednowyrazowy oparty na korpusie Google w odniesieniu do przytoczonego już wcześniej zdania: Jałowy autobus brzmi kotka. Otrzymamy w takim przypadku pewną liczbę większą od zera, gdyż każdy z wyrazów powyższego zdania znajduje swe potwierdzenie w wykorzystywanym korpusie. Wynik taki nie jest jednak zgodny z naszą intuicją, gdyż powyższe połączenie poszczególnych wyrazów nie wydaje się mieć sensu.
Wielowyrazowy model języka bierze już natomiast pod uwagę wystąpienia wyrazów w pewnym kontekście. Na przykład model dwuwyrazowy sprawdza dla danej pary wyrazów, jak często drugi jej element występuje po elemencie pierwszym. Okazuje się przykładowo, że Google wskazuje 461 tys. wystąpień wyrazu “jałowy”, ale tylko raz po tym wyrazie występuje wyraz “autobus”. W związku z powyższym stopień poprawności pary “jałowy autobus” ma wartość bliską zeru.
Dwuwyrazowy model języka wyznacza stopnie poprawności wszystkich par wyrazowych danego zdania (np. jałowy autobus, autobus brzmi, brzmi kotka), po czym mnoży je przez siebie. Zdania pozbawione sensu otrzymują w wyniku powyższej operacji wartości bardzo bliskie zeru.
W podobny sposób można budować trzywyrazowe oraz czterowyrazowe modele języka. Modeli dłuższych niż cztery wyrazy raczej się nie konstruuje.
Najbardziej znane nam zastosowanie modelu języka to podpowiadacz treści SMS-ów. Wystarczy wpisać pierwszy wyraz tekstu, aby system podpowiedział nam wyraz następny. Po kolejnym wpisanym słowie otrzymujemy nowy zestaw podpowiedzi.
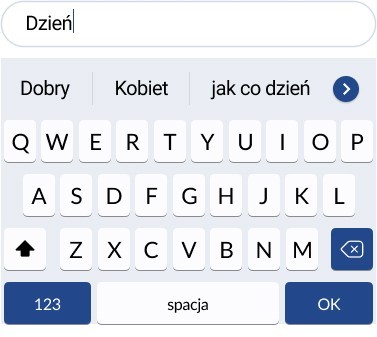
Jak to działa? System podpowiada takie wyrazy, które w połączeniu z poprzedzającymi mają najwyższy stopień poprawności (czyli w korpusie występują najczęściej). Jeśli zatem wpiszemy wyraz dzień, system podpowiada, że według jemu znanego korpusu najbardziej poprawnymi kontynuacjami będą dzień dobry, dzień kobiet lub dzień jak co dzień.
W przypadku tłumaczenia automatycznego system w pierwszym kroku generuje kilka potencjalnych możliwości translacji zdania – różniących się np. doborem spośród wyrazów bliskoznacznych lub ich kolejnością. Model języka podpowiada, która z możliwości jest najbardziej poprawna – i właśnie ta wypowiedź jest podawana przez system jako zdanie przetłumaczone.
Podobną funkcję model języka spełnia w automatycznym rozpoznawaniu mowy. To właśnie model języka decyduje, że podyktowane zdanie “Tak mi dopomóż Bóg” system komputerowy rozpozna prawidłowo (czyli poda jego pisownię zgodną z intencją wypowiedzi), a nie na przykład jako “Tak mi dopomóż Bug” czy “Tak mi dopomóż buk”, choć wszystkie te trzy wersje mają identyczne brzmienie.
Statystyczny model języka to metoda reprezentacji języka naturalnego w oparciu o określony korpus tekstów. Taki model języka “premiuje” wypowiedzi składające się z wyrazów i fraz, które często w tym korpusie występują.
Pewnym ograniczeniem statystycznego modelu języka jest jednak fakt, że bierze on pod uwagę wyłącznie powiązania pomiędzy wyrazami z sobą sąsiadującymi. Przeanalizujmy bowiem następujące przykładowe zdanie:
Umowa powyższa zawiera błędy merytoryczne, więc nie mogę jej podpisać.
W zdaniu tym wyrazy “umowa” oraz “podpisać” są od siebie mocno oddalone (oddziela je od siebie aż osiem innych wyrazów). Statystyczny model języka nie jest w stanie wykryć, że zachodzi pomiędzy nimi jakiekolwiek powiązanie znaczeniowe, a przecież dotyczą one tej samej czynności: podpisania umowy.
Tego typu odległe powiązania są natomiast w stanie wykrywać tzw. neuronowe modele języka. Ich podstawowa rola jest co prawda podobna do funkcji modeli statystycznych – określają one stopień poprawności wypowiedzi względem pewnego korpusu tekstów. Różnica pomiędzy nimi związana jest jednak z metodą obliczania powyższego stopnia poprawności – dzięki zaawansowanej strukturze sieci neuronowych brane są pod uwagę również zależności pomiędzy wyrazami odległymi.